

Recently, there has been a lot of controversy in AI for the ‘ability’ to identify race from medical imaging, with AUCs up to 0.99 in being able to predict whether a patient is Black from the chest x-ray images alone. Our research group have been trying to understand why that is, and think a significant proportion of effect is due to confounding in the datasets, but it’s an excellent area to study causal inference in AI. Let me explain my thought process.
First, it’s widely accepted that race is a social construct, where what a race means is different across time and place. Asian means something in the UK different than the USA and ‘Colored’ means something different in South Africa than in USA. Second, people are rather inconsistent in how they self-report race at different times and place. The UK government linked various census and healthcare datasets together by patient identifier, and showed that there was inconsistency in how individuals self-identified across different forms. How can a computer vision model tell where the person is from and where its being run?

Messy labels create an upper bound to how well an AI model can perform in a prediction task. I wrote this paragraph referring to evaluation of heart function as a prediction task, but this is equally true in detecting race.
Paradoxically, this makes writing ML papers in imaging hard - there’s an inherent upper bound on the performance of AI algorithms trained on human labels, and why there’s clearly shenanigans when the AUC or R2 is unrealistically high. (Intuitively, lets pretend we have a perfect AI model and the correlation between clinician A and clinician B is 0.85. If an AI model’s correlation is perfect with clinician A (the R2 is 1 for the perfect algorithm), the exact same AI would have an R2 with clinician B would be 0.85.) How are we so lucky to have chosen clinician A as our ground truth?
How can there be an AUC of 0.99 when labels are inconsistent across time and place (and limited biological basis and classifications vary based on where the imaging is done)? I don’t think that’s possible unless there’s shortcuts and confounding variables, but this is a perfect place for causal inference.
Causal Inference
Broadly speaking, AI is identifying associations (often between diagnostic data and diagnoses when it comes to medical AI). But AI thought of as mysterious and ‘black-box’, many of the known standards regarding rigor for association studies are often not adhered to. Because it seems like every other day, AI is being touted as doing something super-human, we often neglect to review the evidence and critically apply known concepts in econometrics, statistics, and just plain-old common sense in understanding some of these algorithms.
I’d like to walk through an example. A couple of years ago, a paper was published showing that AI can be used to diagnose liver disease (cirrhosis) simply by looking at electrocardiograms (cheap, common diagnostic test for the heart). This seems great as cirrhosis can be missed in early forms and screening important to treat reversible causes and minimize harm. However, how is it that a diagnostic test for the heart can identify liver disease?
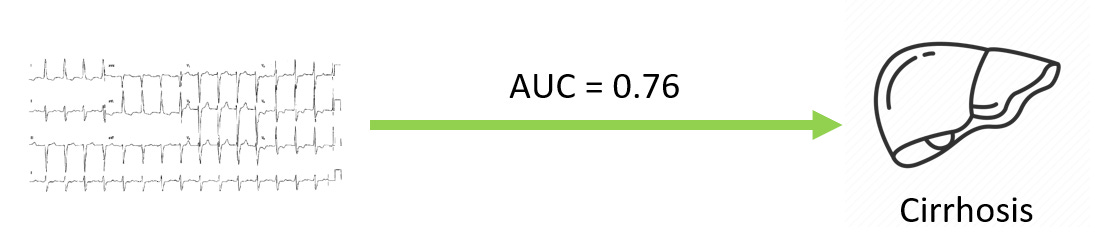
Actually, one way to understand this is recognizing that sometimes, end-stage liver disease can be strikingly obvious. When decompensated, liver cirrhosis can cause peoples' skin to turn yellow (jaundice) and for there to be extensive fluid collection in the abdomen (ascites). In this situation, a fancy test is not needed, because it is strikingly obvious from across the room. But also coincidentally, the ECG would also show changes, as fluid accumulation dampens the electrical signals from the heart, and while not the most straightforward way to diagnose ascites, it would be readily identifiable on an AI model.
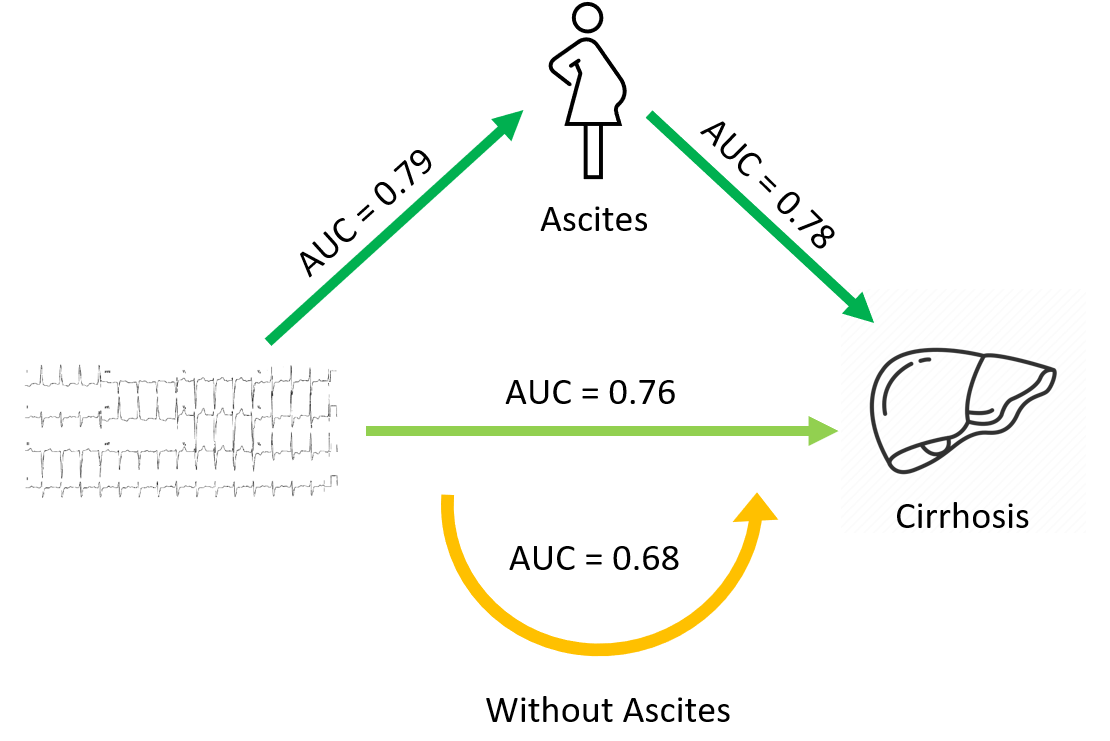
To test this hypothesis, one could evaluate the performance of AI models to detect cirrhosis without ascites vs. cirrhosis with ascites, and also evaluate an ascites model’s ability to identify cirrhosis. In fact, we did this - and showed that our cirrhosis model performed much worse in the subset of patients that did not have a concomitant diagnosis of ascites. As well, a model trained to detect ascites had as good (maybe even better) performance in identifying patients with cirrhosis. To us, it seemed quite clear that this set of experiments showed that a big part of the ability to predict cirrhosis from ECGs is the ability to detect ascites.
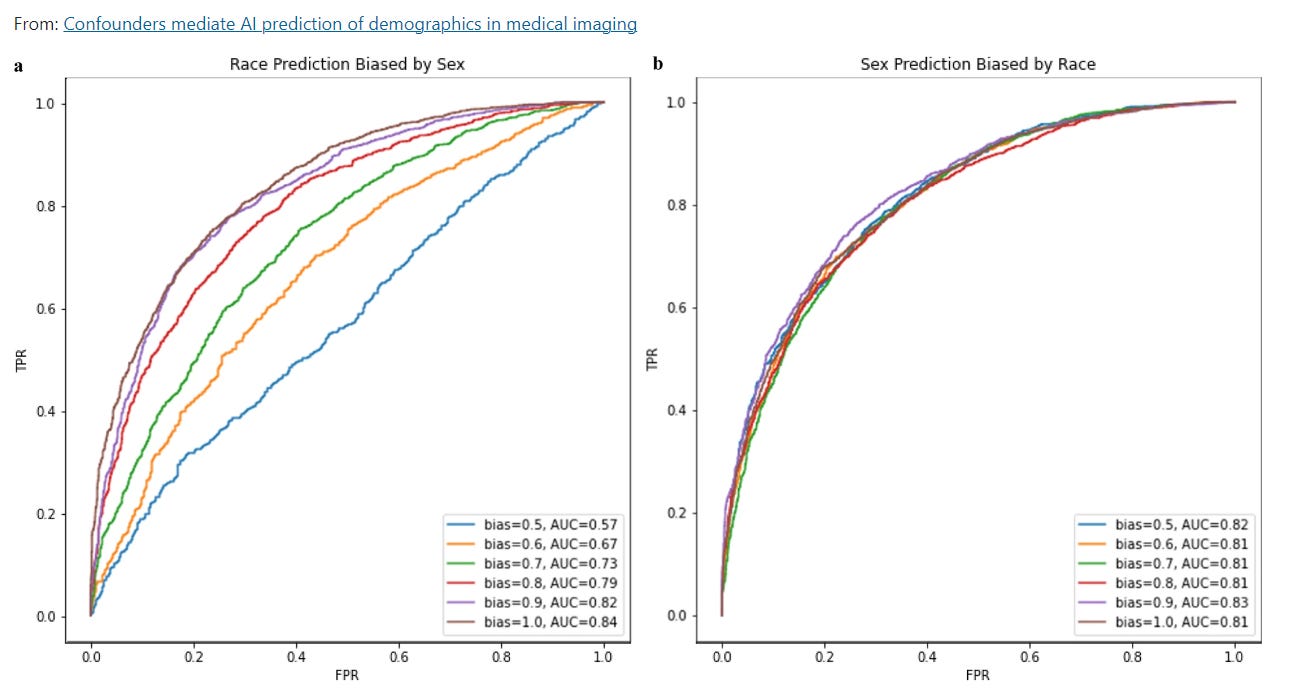
We suspect a similar set of circumstances happen with AI prediction of race from medical imaging. In large healthcare system databases, Black patients tend to be sicker and older than the average non-Black patient (in part due to differences in access to healthcare), and we suspect that AI models trained to predict race is rather picking up these differences in disease severity that actually have nothing to do with race. Thus, we did a similar set of experiments, where we evaluated with how big of an impact biased datasets influence model performance and found that models predicting race were quite sensitive to confounders in a way that models predicting other characteristics with more of a biological basis.
Non-Causal Inference
What does this all mean for clinicians? Extraordinary claims require extraordinary evidence. More and more, there are sales people knocking on our doors selling AI technologies with incredible claims that might not be backed by strong science. For example, there are AI companies selling ECG algorithms to detect hypertrophic cardiomyopathy, however these models are trained with age- and sex- matched controls that do not have left ventricular hypertrophy. Ultimately, those algorithms are fancy LVH classifiers, and we can already tell LVH from ECGs. Trained where there’s a big difference in cases and controls, those algorithms won’t be able to tease apart the patient with AS, long standing hypertension or end-stage renal disease from HCM.
Imagine creating a algorithm to determine whether a voter is Republican or Democrat. However, in the training data, you chose Republicans from a Los Angeles baseball game and Democrats from the Coney Island eating contest. It is incorrect to say “wearing a Dodgers hat increases your chance of being Republican” or “if you eat hotdogs, you are more likely to be a Democrat”. In fact, if you were doing econometrics or performing a case-control study, reviewers will reasonable critique that such an approach is unbalanced even if it generates a very high hazard ratio for some metrics.
It’s infinitely easier to identify a Dodgers hat or hot dog from an image than political leanings. With Occam’s razor, AI models can shortcut on the more obvious phenotypes. In the same way, age can be a very obvious shortcut, when it comes to unbalanced cases and controls (say, for HFpEF vs not). It’s been well published that age and sex are strongly predicted by medical imaging. When there is a difference in features that are detectable by medical imaging, that’s likely the driver between distinguishing cases and controls. The onus is on the developers to prove its value when its a more challenging phenotype.
Extraordinary claims require extraordinary evidence. That’s where clinical trials and implementation science can come in. Right now, the FDA does not require RCTs or prospective evidence to clear an AI algorithm, so the responsibility is on the clinicians to carefully evaluate the utility and efficacy of medical AI, Otherwise, we might just be using Dodgers hat detection algorithms.